


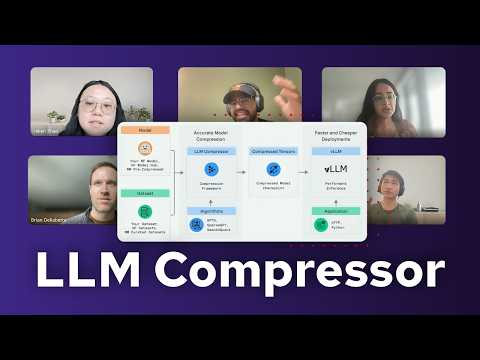
Take a closer look at the evolution of llm-compressor in this in-depth session featuring contributors from Red Hat and the open source community.
Topics covered:
00:00 LLM Compressor
01:21 v0.6.0 feature breakdown
02:28 API usage for compression workflows
12:39 Calibration pipelines: basic, data-free, and sequential
25:57 Internal modifier lifecycle and callback design
34:17 AWQ and FP4 quantization algorithms
48:06 Integration with OpenShift AI for scalable model optimization
49:51 Upcoming roadmap and future FP4 enhancements
You’ll learn how LLM Compressor enables faster compression, lower memory usage, and support for cutting-edge quantization formats, including NVIDIA’s NVFP4. The session also walks through sequential onloading, dynamic calibration strategies, and the internals of the modifier lifecycle.
Whether you’re optimizing models for research or deploying to production, this session is packed with insights into modern LLM compression workflows.
Learn more and get started: https://github.com/vllm-project/llm-compressor
Subscribe to @redhat for more demos, deep dives, and walkthroughs.







